
1. Questions
Pedestrian safety is a major concern in the transportation industry since pedestrians are the most vulnerable group to be injured in motor vehicle-related traffic collisions (Beck, Dellinger, and O’neil 2007; Toronto Public Health 2012, 2015; Pour-Rouholamin and Zhou 2016). In Toronto, Ontario, pedestrians accounted for 44% and 62% of all fatalities from traffic collisions in 2022 and in 2023 (as of October 16, 2023), respectively (City of Toronto 2023). An understanding of the relevant factors that contribute to injury severity due to collisions can provide insights to improve pedestrian safety. Accordingly, by incorporating spatial information, this study explored the role of different factors such as demography, pedestrian and drivers’ conditions, collision characteristics, road characteristics, and weather in predicting pedestrian injury severity from automobile-related collisions.
2. Methods
The traffic collision data of the City of Toronto from 2006 – 2022 is obtained from the Toronto Police Service’s public safety data portal (http://data.torontopolice.on.ca/datasets/ksi/data). The injury severity of each individual involved in the collision was recorded in five categories: None – Minimal – Minor – Major – Fatal. Collision-related data were also available in the database, including age of the individual(s) involved, type of vehicle(s) involved, condition(s) of the individuals involved, time of occurrence, visibility, lighting condition, collision location (e.g., intersection, non-intersection, near private driveway), type of traffic control at the collision location, road condition, etc. As this study focused on automobile-related pedestrian injury, collision data involving other vehicle types were excluded from the analysis. The information on drivers’ and vehicle passengers’ injury levels in pedestrian-automobile collisions were also excluded but drivers’ age and information on their conditions during the collision (e.g., impaired driving, inattentiveness, etc.) were included to explore whether these factors contribute to pedestrian injury severity. Finally, 2021 observations were selected for analysis. The distribution of injury severity class is – Fatal: 13%, Major: 80%, Minor: 4%, Minimal: 2%, None: 1%. Please refer to the Supplemental Information to be informed about the class imbalance in the dataset and how it has been resolved.
The analysis was conducted using a non-parametric machine learning technique known as random forest (RF) classification model which is widely used in injury severity analysis (e.g., Li et al. 2017; Rezapour et al. 2021). Predictor variables used in model development are presented in Table 1. As multicollinearity does not affect the prediction accuracy in RF algorithm, no tests were conducted to check for multicollinearity among the predictors.
One of the frequently reported limitations of machine learning models is that there is no standard method of incorporating spatial information into the model, and as a result, they cannot minimize spatial autocorrelation (Islam et al. 2022). To address this limitation, a RF model for pedestrian injury severity prediction in pedestrian-automobile collisions was developed first without incorporating spatial information (model 1). To incorporate spatial information, two different approaches were followed. First, a RF model was developed where latitude and longitude were used directly as predictors (model 2). Second, the eigenvector spatial filter method was applied to extract approximated eigenvectors from spatial coordinates of the collision location [see Supplemental Information section]. Later, the vector for all approximated eigenvectors (EV) was extracted and included as a predictor within the random forest model (model 3). A comparison of three RF models was made to determine which model demonstrates better performance in terms of predicting pedestrian injury severity in pedestrian-automobile collisions.
The RF models were developed based on 80% of the observations (training dataset: 1617 observations) and tested on the remaining 20% (testing dataset: 404 observations). Two hyperparameters (mtry and ntree) were specified. The mtry parameter controls how many predictors are to be considered in a decision tree at any given point in time. The ntree parameter represents the number of decision trees to be developed for the RF models. A 10-fold cross-validation procedure is used to select the optimal hyperparameter values which involves testing multiple values of the hyperparameters and selecting the optimal values[1] (Ahmed and Roorda 2021). The values tested for the hyperparameters are: mtry = 1 to 10 and ntree = 100, 150, 200, 300, 400, 500, 1000. Based on the results of the cross-validation procedure, the following hyperparameter values were selected[2]:
-
Model 1 (includes no spatial information): mtry = 4, ntree = 100,
-
Model 2 (includes latitude and longitude): mtry = 5, ntree = 400.
-
Model 3 (includes EV): mtry = 6, ntree = 150.
The R package “spmoran” (Murakami 2023) was used to extract the vector for all approximated eigenvectors (EV), “ROSE” (Lunardon, Menardi, and Torelli 2014, 2021) was used to resolve the data imbalance issue, and “randomForest” (Liaw and Wiener 2022) was used to develop the RF models.
3. Findings
Table 2 shows the prediction accuracy of the three models on both training and testing datasets. Prediction accuracy was calculated by developing a confusion matrix of the actual injury classes and predicted injury classes based on the developed models. The inclusion of spatial information in the RF model improves the prediction performance of the models in the training dataset. In all three models, prediction accuracy is slightly degraded in the testing datasets compared to the corresponding training models. However, the testing dataset is the real-life field data which was not used in the training of the prediction models. Based on the results, it can be concluded that the trained models 1, 2 and 3 will be able to predict out-of-sample injury severity class with 83.17%, 84.9% and 81.69% accuracy, respectively.
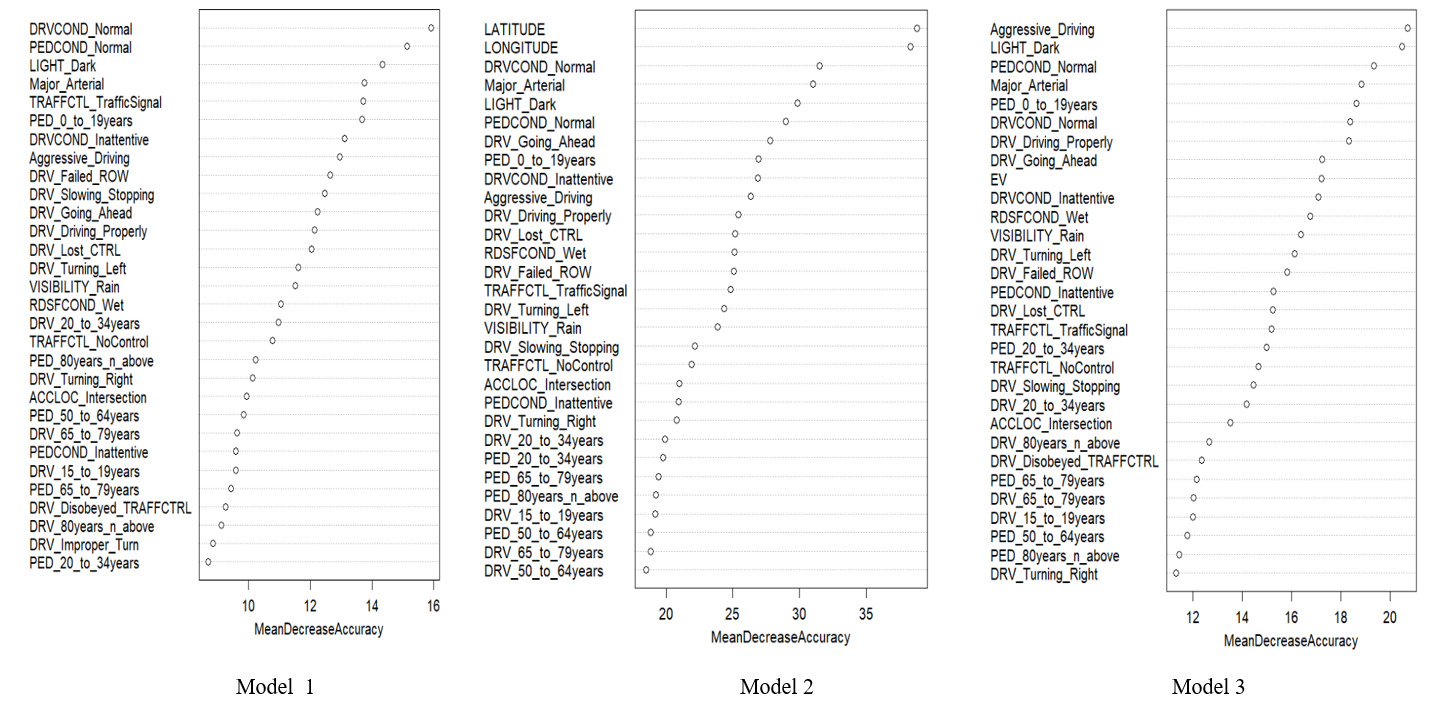
The Mean Decrease Accuracy plots of the three RF models are presented in Figure 2. These plots express how much accuracy the models lose by excluding each predictor.[3] The plots for both models 2 and 3 show the importance of spatial information in predicting pedestrian injury severity. Direct use of latitude and longitude plays a more important role in predicting injury severity than EV as model predictors.
The developed model can be used in predicting injury severity in pedestrian-automobile collisions in Toronto. The study results also indicate the importance of developing appropriate countermeasures to increase pedestrian safety, especially related to aggressive driving, and drivers’ and pedestrian conditions. In terms of future work, other machine learning techniques such as gradient boost, XGBoost, and support vector machine (SVM) can be developed and a comparison of the prediction accuracies of the models can be used to determine the optimal prediction model for pedestrian injury severity in pedestrian-automobile collisions in Toronto.
It is expected that enough trees and parameters (in each tree) are considered to stabilize the prediction error and optimize model performance, but using too many trees or parameters involves more computational time.
A slight difference in hyperparameter values is expected as there were differences in variables (i.e., spatial information) included in the dataset.
The first thirty predictors are presented in descending order. The more the accuracy suffers, the more important the predictor is for the successful prediction of classification.