
1. Questions
Origin-destination (OD) datasets are widely used in transport planning to efficiently represent aggregate travel behavior. Despite the emergence of ‘big data’ sources such as massive GPS datasets, OD data continues to play an established — if not central — role in 21st century transport planning and modelling. Recent applications range from analysis of the evolution of urban activity and shared mobility services over time (e.g. Shi et al. 2019; Li et al. 2019) to inference of congestion and mode split (Bachir et al. 2019; Gao et al. 2021).
There has been much written on optimal zoning systems for and geographic representations of OD data (e.g. Openshaw 1977; Boyce and Williams 2015). Recent papers have presented new methods for OD dataset validation (Alexander et al. 2015), aggregation (He et al. 2018; Liu et al. 2021), disaggregation (Katranji et al. 2016) and location of ‘connectors’ joining zone center points (centroids) with the surrounding network (Jafari et al. 2015). Broadly, there are two approaches to converting OD data into geographic representations for transport modelling:
-
Centroid to centroid representations, a common approach involving the simplifying assumption that all trip destinations and origins can be represented by (sometimes population weighted or aggregated) zone centroids (Guo and Zhu 2014; Martin et al. 2018).
-
Subdividing zones (also referred to as transport analysis zones, TAZ) at which data is available to subzones centroids (Opie, Rowinski, and Spasovic 2009) or ‘centroid connectors’ or simply ‘connectors’ “between trip ends and zonal anchors” using stochastic or deterministic approaches (Leurent, Benezech, and Samadzad 2011; Friedrich and Galster 2009).
In this paper we present a new approach which, unlike established approaches which convert centroid based desire lines to routes and then route networks (Morgan and Lovelace 2020), allows the user to adjust start and end locations based on variables such as transport network density, residential density or size of commercial buildings acting as trip attractors. This ‘jittering’ approach is flexible, enabling the user to adjust the level of disaggregation, the location of start and end points from which disaggregate OD pairs are sampled, and weights representing the importance of different trip ‘originators’ and ‘attractors’.
OD data jittering can is a simple, transparent and flexible pre-processing stage that aims to represent the diffuse nature of travel patterns. This is particularly important when designing for active travel (Buehler and Dill 2016), explaining the choice of input data to illustrate the technique in this paper: it was developed in response to feedback from Edinburgh City Council (who funded a project based on the research) that route networks based on the Propensity to Cycle Tool approach (Lovelace et al. 2017) were too sparse. Jittered OD data can be used with existing transport modelling workflows developed around centroid-based methods, as the basis of route network assignment, uptake modelling, and route network generation workflows (Morgan and Lovelace 2020). We refer to the approach as jittering, which means adding random noise for data visualization (Wickham 2016).
The jittering approach presented in this paper was motivated by the following question:
How can OD data representing trips between large geographic zones be used more effectively, to generate diffuse route networks of current or potential flow to inform local interventions?
2. Methods
The approach was developed to support public sector transport planning in Edinburgh, UK. The original study area was Edinburgh City Council, a major economic hub with ambitious plans for investment in active travel, making evidence to support investment where it will be most beneficial key. For the purposes of this study we focus on a comparatively small area around central Edinburgh. We focus in this paper on walking trips in this central area because much research into route networks has focused on cycling and, because walking trips tend to be short, they create a need to convert aggregated OD datasets into diffuse route network representations of travel. Input datasets developed for this paper can be downloaded using reproducible code that accompanies the paper; see code at https://github.com/robinlovelace/odjitter to fully reproduce the findings.
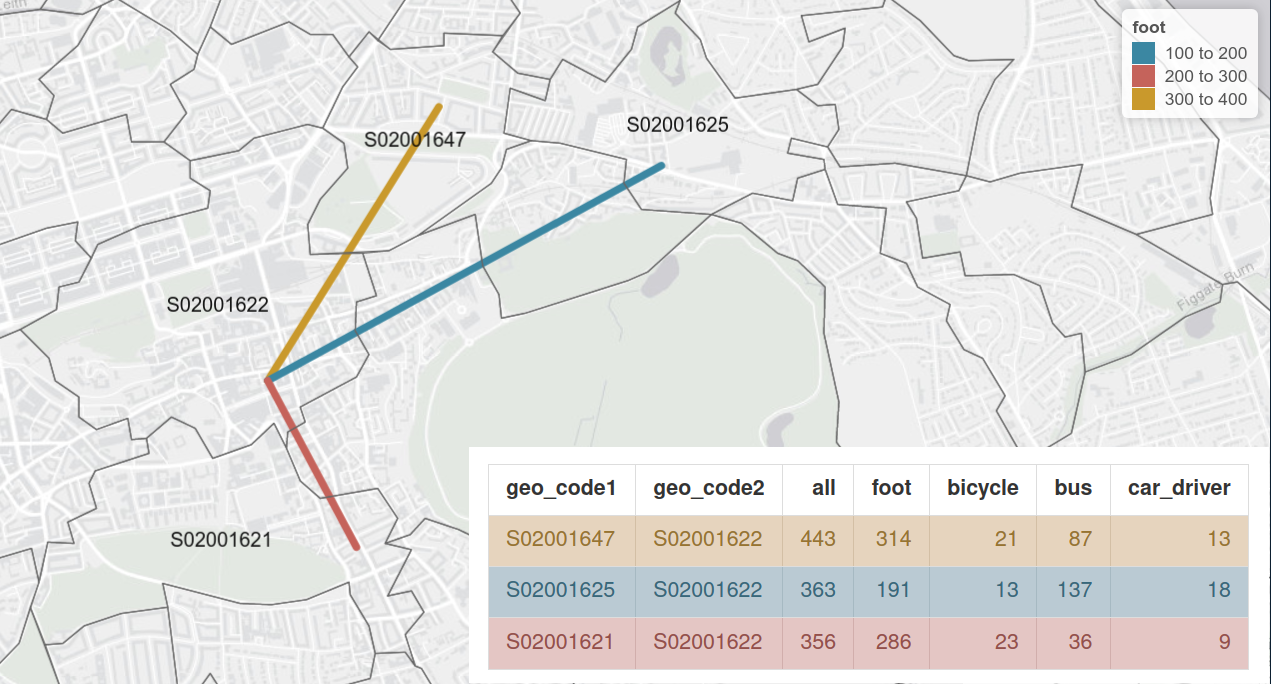
Beyond the zone data illustrated in Figure 1, the input dataset consisted of open access OD data from the 2011 census. The OD data can be represented as both tabular and, when start and end points are assigned to centroids within each zone, as geographic entities, as illustrated in a sample of three OD pairs presented in Figure 1. To generate the route networks presented in Figure 4 we used the OpenStreetMap Routing Machine (OSRM) with the profile set to ‘foot’.
_and_geographic_form_(in_the_ma.png)
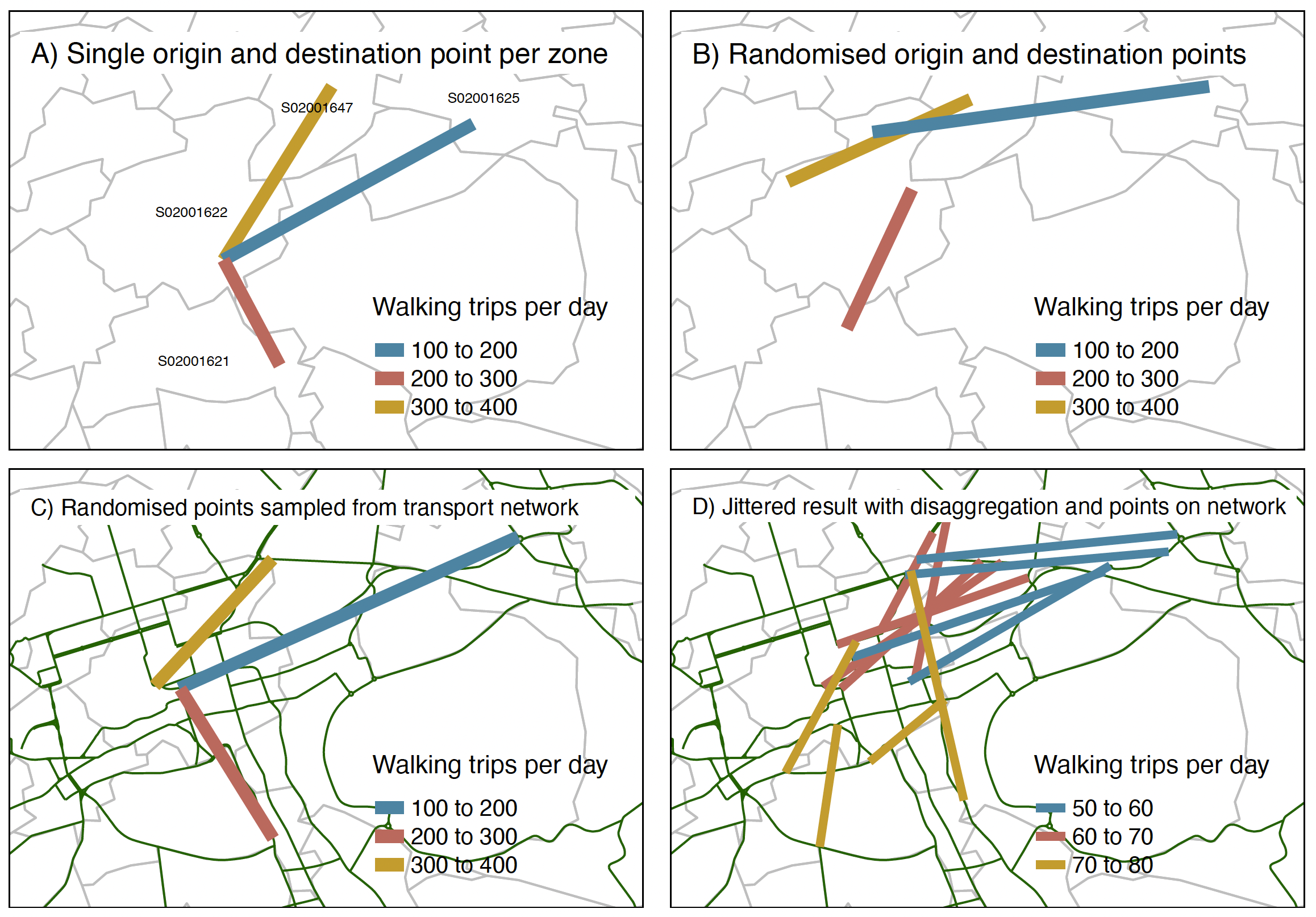
The key elements of the jittering approach outlined in this paper are described in the following sub-sections, and are perhaps best understood visually, as illustrated in each of the facetted maps in Figure 2. The subfigures show the flexibility of approach, with C) and D) demonstrating the use of vertices on the road network as start and end points, building on the observation from spatial network analysis that the density of the transport network is a reasonable proxy for travel demand (Cooper 2018). Other refinements including weighted subpoints could be used when data sources (e.g. building footprint areas) are available.
_data_with_a_minima.png)
2.1. Sampling origin and destination points
Key to jittering is ensuring that each trip starts and ends in a different place. To do this, there must be ‘sub-points’ within each zone, one for each trip originating and departing.
The simplest approach is simple random spatial sampling, as illustrated in Figure 2 (B), which involves generating random coordinate pairs. This approach has the advantages of simplicity, requiring no additional datasets, but has the disadvantage that it may lead to unrealistic start and end points, e.g. with trips being simulated to start in rivers and in uninhabited wilderness areas.
To overcome the limitations of the simple random sampling approach, the universe of possible coordinates from which trips can originate and end can be reduced by providing another geographic input dataset. This dataset could contain known trip attractors such as city centers and work places, as well as tightly defined residential ‘subzones’. For highly disaggregated flows in cases where accurate building datasets are available, building footprints could also be used. A useful, and widely available (Barrington-Leigh and Millard-Ball 2017), input for subsampling is a transport road network, as illustrated in Figure 2 (C). Additional refinements to the stochastic selection of origin and destination based on weights relating to other datasets are possible, as discussed in the final section.
2.2. Disaggregation
Both of the jittering techniques outlined above generate more diffuse route networks. However, a problem with OD datasets is that they are often highly variable: one OD pair could represent 1 trip, while another could represent 1000 trips. To overcome this problem a process of disaggregation can be used, resulting in additional OD pairs within each pair of zones. The results of disaggregation are illustrated geographically in Figure 2 (D) and in terms of changes to attributes, in Tables 1 and 2. As shown in those tables, updated attributes can be calculated by dividing previous trip counts by the number of OD pairs in the disaggregated representation of the data, 5 in this case. To determine how many disaggregated OD pairs each original OD pair is split into, a maximum threshold was set: an OD pairs with a total trip count exceeding this threshold (set at 100 in this case) is split into the minimum number of disaggregated OD pairs that reduce the total number of trips below the threshold.
3. Findings
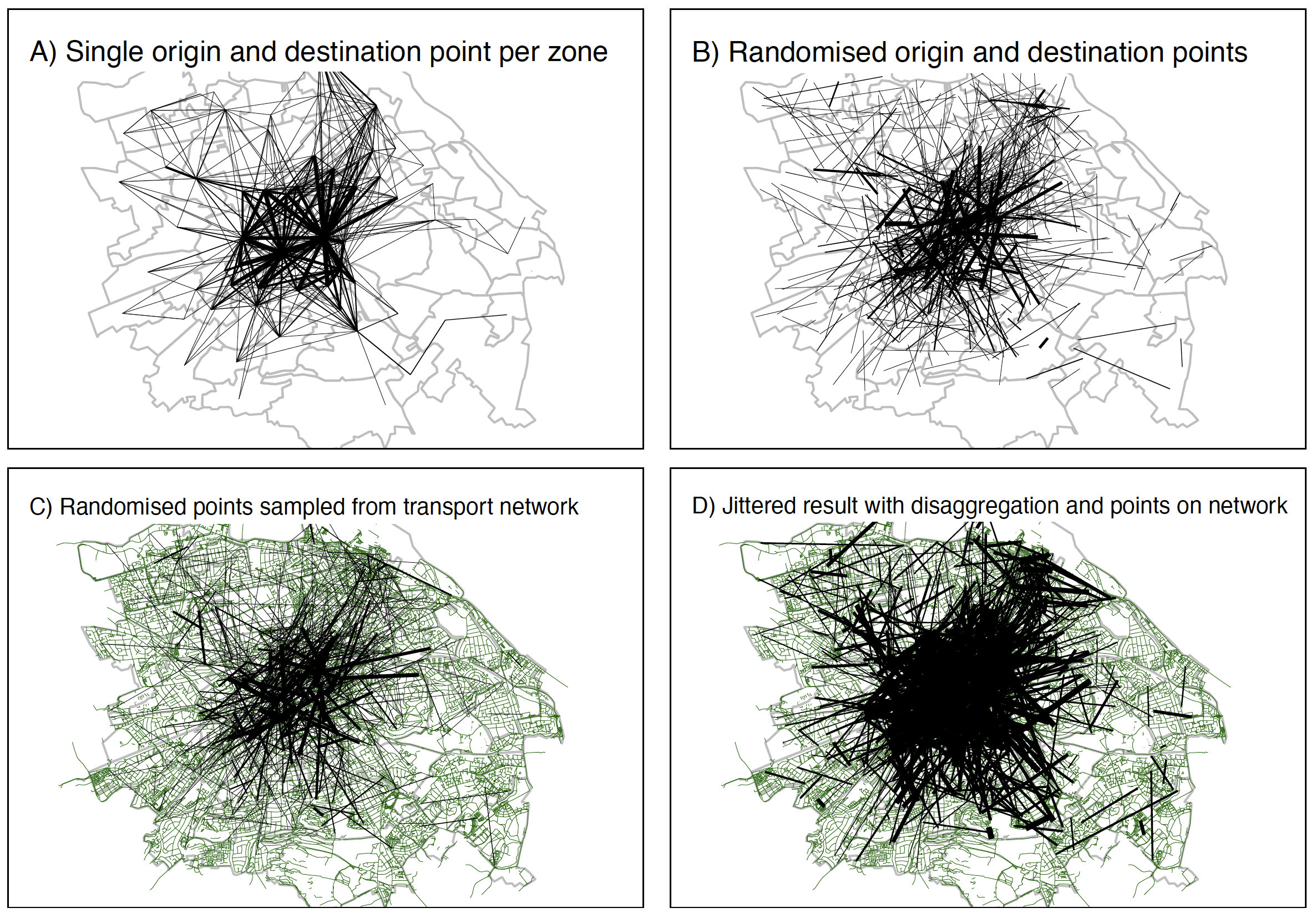
We found that jittering generates desire lines, and route networks, that are more geographically diffuse than those resulting from the established centroid-based approach. Figure 3 shows the use of simple random sampling and sampling nodes on transport networks with reference to a real world example. While the simple random sampling method of jittering presented in Figure 3 (B) may be appropriate in some specific cases, we advocate using pre-defined sub-points. Using sub-points representing vertices on the transport network, as illustrated in Figures 3 C and D, is supported by ‘spatial network analysis’ (SNA) approaches to transport modelling (e.g. Cooper 2018). Weighted points representing trip origins and destinations such as houses and commercial buildings could also be used.

The results of converting the desire lines to routes and then route networks are illustrated in Figure 4, which shows progressively more diffuse networks. Greater disaggregation leads to more diffuse networks as shown in Figure 4.
_and_od_data_that_has_been_jitt.png)
The advantages of this approach include simplicity, low computational cost and flexibility, with disaggregation (and network diffusion) levels adjusted depending on requirements. Disadvantages relate to the use of random number generators (RNG), which can reduce reproducibility (overcome this by setting a ‘seed’, which makes the findings reproducible) and influence findings (generate more than one set of results and undertake testing to mitigate this drawback). Jitting is particularly well suited to modelling walking and cycling, which require diffuse networks. Taking disaggregation further, the approach can generate one desire line per trip that could feed into agent based models (ABM) such as A/B Street and MATSim (Carlino et al. 2022; Horni, Nagel, and Axhausen 2016). Jittering has few input data requirements, enabling its use in situations where sub-zones are unavailable.
This is, to the best of our knowledge, the first time that stochastic spatial sampling and disagreggation of OD data has been described in a single approach. The approach is implemented in the open source Rust crate odjitter. Implementations in R packages od and odjitter, an interface to the Rust implementation, enable others to reproduces the findings, raising the possibility of interfaces to other languages.
The results also raise research questions, including:
-
Are the jittered results measurably better when compared with counter datasets on the network?
-
How would results from jittering OD data compare in other situations, e.g. to model motor traffic?
-
Which jittering settings (including sampling strategies and levels of disaggregation) represent the best ‘boom for buck’ in terms of network accuracy relative to computational requirements?
-
And can further refinements, for example sampling with weights to increase the proportion of trips associated with large buildings and commercial centers, or modifying disaggregation threshold values depending on variables such as zone size, improve results?
Before further refinements are made, we advocate empirical research to validate the jittering approach outlined in this paper as a foundation for further work on OD data pre-processing and disaggregation. Such research requires case studies that have both good open OD data and good observed travel behavior data, for example from manual and automatic counters at point locations on the network (Lindsey et al. 2013) and other sources of data such as trajectory datasets from GPS devices (Zheng et al. 2016).
Acknowledgements
This work is funded by the Economic and Social Research Council (ESRC) & ADR UK (grant number ES/W004305/1) as part of the ESRC-ADR UK No.10 Data Science (10DS) fellowship in collaboration with 10DS and ONS (who funded Robin Lovelace).
This research was supported by the PARSUK Portugal-UK Bilateral Research
Fund, from the Portuguese Foundation for Science and Technology (FCT).
We would like to acknowledge the GeoRust community (https://georust.org) for developing core dependencies and implementation advice.