

Questions
Human-powered transportation such as walking, cycling and using a wheelchair (known as active travel [AT]) is associated with numerous benefits, such as improving physical and mental well-being. Additionally, AT has demonstrated resilience throughout the COVID-19 pandemic (Teixeira and Lopes 2020). Spatial dependence has been demonstrated for walking (Wei et al. 2016), as well as bicycle and pedestrian injury counts (Narayanamoorthy, Paleti, and Bhat 2013; P. Chen and Shen 2016). We believe cycling is no exception, thus accounting for spatial heterogeneity is essential to improve the cycling model interpretation.
Previous AT-related studies have primarily employed traditional data sources such as cordon counts and non-spatial regression model techniques such as the Poisson (Hong, McArthur, and Livingston 2020; C. Chen et al. 2020), mixed logit (Kang and Fricker 2013; Lind, Honey-Rosés, and Corbera 2020), negative binomial (NB) (C. Chen et al. 2020; Raihan et al. 2019) and ordinary least squares (OLS) (Hong, McArthur, and Stewart 2020; Boss et al. 2018) models. However, the ubiquity of information and communications technology has enabled users to generate data that include the three Vs (volume, velocity and variety) as well as fine spatial granularity, denoted as crowdsourced datasets (Ali et al. 2016). This type of data can incorporate the spatial component of AT, which has previously been deemed as inadequate in studies using traditional data sources.
Building on previous work where we spatially modelled cyclists’ route choices in the City of Glasgow (Alattar, Cottrill, and Beecroft 2021), here we aim to identify the contribution of crowdsourced datasets to improve data modeling performance via the following objectives:
-
To examine the spatial dependence of cycling within the study area; and
-
to compare three regressive models, namely, the OLS, spatial lag model (SLM) and spatial error model (SEM).
Methods
We employ two types of crowdsourced datasets in this work: i) the Strava 2018 dataset, containing the number of cycling trips on each street intersection (CCT), which is obtained from Strava app users who record, track and share their physical activities; and ii) a dataset generated using the python toolkit OSMnx to obtain the Glasgow street network from the collaborative worldwide mapping project OpenStreetMap (Boeing 2017). Moreover, street network centralities (degree [DC], betweenness [BC], closeness [CC], and eigenvector [EC]) are quantified, as explained in Table 1.

The QGIS NNJoin plugin (version 3.4.14-Madeira) was used to prepare the data, allowing for the integration of CCT with the street network centralities. The variables were then logarithmically transformed with GeoDa (version 1.14.0) to reduce data skewness. Thiessen polygons were created around each Strava intersection point to determine neighboring intersections using Queen’s contiguity matrix. Thiessen polygons define the boundary of each intersection by allocating the surrounding location to the closet intersection (Yamada 2016). Figure 1 presents the results of such an exercise, where the neighboring intersections for each intersection are defined based on the shared corners and edges of the Thiessen polygons.

We assess the spatial dependence of cycling using Univariate Moran’s I analysis, where values close to +1 (-1) indicate 100% spatial clustering (dispersion) and values close to 0 indicate spatial independence. We then implement the OLS model by setting CCT as the dependent variable and the street network centralities as the independent variables. We perform multicollinearity analysis and residual diagnostics for heteroskedasticity and spatial dependence to examine the adequacy of OLS. This is followed by the implementation of SLM and SEM to incorporate lag coefficients. More specifically, the SLM lag coefficient (ρ) is introduced by the dependent variable spatial dependence while the SEM lag coefficient (λ) is introduced by the residuals’ spatial dependence. All analyses were conducted using GeoDa, with the exception of the variance inflation factor (VIF), which was calculated using R.
Findings
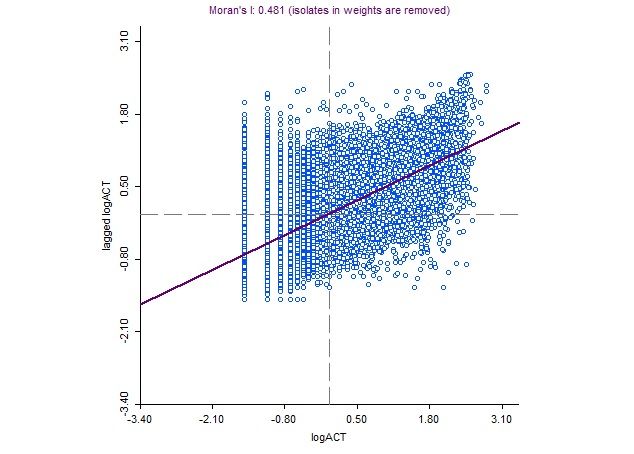
Cycling is observed to be significantly spatially autocorrelated (Moran’s I = 0.481, P-value < 0.05), whereby locations with a high (or low) number of cycling trips tend to cluster. Figure 2 presents the logarithm of the number of cycling trips.The following underlying factors may influence this spatial variation: i) proximity to cycling infrastructure and amenities, which encourage individuals to cycle (Lee, Won, and Ko 2015); ii) area affluence, for example Glasgow cycling propensity is more pronounced in affluent populations (Muirie 2017); and iii) safety, where Jacobsen (2015) referred to “safety-in-numbers”, a term encompassing the inclination of cyclists to cycle (as they feel safer) in places where cycling is prevalent.

The mean of VIF was 1.06, indicating the absence of multicollinearity among the independent variables (no excessive redundancy). Table 2 reports the results of OLS, SLM and SEM for 12,354 observations, with LogCCT as the dependent variable and the logarithm of the street network centralities as the independent variables. OLS determined a significant weak positive correlation between LogCCT and the independent variables. However, the presence of residual heteroskedasticity and spatial dependence violate two key assumption of OLS. In particular, OLS assumes homoskedasticity (as opposed to heteroskedasticity), which occurs when there is a constant error term variance. The significance of both Breusch-Pagan and Koenker-Bassett tests indicate heteroskedasticity (Rosenthal 2017). Furthermore, OLS assumes the spatial independence of the residuals, which according to Moran’s I and the Lagrange Multiplier, is found to be statistically significant (Anselin 2013). These violations suggest the inadequacy of OLS, and the need to instead fit spatial models.
The SEM (R2 = 0.43) exhibits a moderate goodness-of-fit and greater value compared to that of SLM (R2 = 0.408) and OLS (R2 = 0.165). Additional model selection criteria (LogL, AIC and SC) reveal the ability of SEM to better explain CCT compared to SLM and OLS. Greater values of R2 and LogL and lower values of AIC and SC indicate a better fit. To verify these findings, we have applied a bootstrapping approach, where we preform similar analyses on Glasgow City Centre (with 1,711 observations). The results of this process echo our findings with slightly better performance (see Supplemental Information). Thus, accounting for the spillover effect of the dependent variable results in the formation of a more accurate model. The reader is referred to Alattar, Cottrill, and Beecroft (2021) for a detailed interpretation of the model.
Thus, we can conclude that, based on the spatial dependance of OLS residuals and the model selection criteria, in some cases the inadequacy of OLS can be remedied by adopting spatial models. Crowdsourced data supports the implementation of such a robust method given its fine spatiotemporal resolution. In addition to the street network centrality indices, the implementation of SEM was able to account for the inherent spatial variation. This work indicates the potential of high spatial resolution crowdsourced data to model numerous AT applications, which can consequently result in more informed interventions.
Acknowledgments
The authors would like to acknowledge the following data source:
Strava Inc. Economic and Social Research Council. Strava Metro data - Scotland, Glasgow, Manchester, Tyne and Wear [data collection]. University of Glasgow - Urban Big Data Centre.