
Various models have been proposed to generate structures that share similarities with real-world cities. The correlated percolation model combines an exponential radial gradient with correlated random numbers (Makse, Havlin, and Stanley 1995). However, the largest city is too big and consequently omitted when Zipf’s law for cities, i.e. a power-law size distribution with specific exponent, is validated. The model by Schweitzer & Steinbrink (1998) is based on two processes, the emergence of new clusters and cluster growth. In this model a similar problem is encountered – due to coagulation the largest cluster dominates the growth process. The authors avoid this by excluding the largest cluster from growth.
We consider the Stochastic Gravitation Model (SGM) (Rybski, García Cantú Ros, and Kropp 2013; Li, Rybski, and Kropp 2021; Rybski and Li 2021). In this approach, the probability that a site is converted from non-urban to urban is given by
\[q_{i} \sim \frac{\sum w_{j} d_{i, j}^{-\gamma}}{\sum d_{i, j}^{-\gamma}}\tag{1}\]
where is the main parameter and is the Euclidean distance between sites and The structures generated by the SGM also exhibit a largest cluster that is too large compared to the smaller ones.
The exponent characterizes what is also known as “friction of distance” or “friction of space” (Cliff, Martin, and Ord 1974). Couclelis (1996) describes a “[…] ‘glue’ holding cities together […] to overcome the friction of distance for the purpose of efficient communication […]”. In economic terms, distance translates into costs which are to be minimized (Friedmann 1956). Small allows new urban areas to be seeded further away and they do not have to be adjacent to old ones.
Here we propose a new model representing a combination of the SGM with Diffusion Limited Aggregation (DLA) (Witten Jr. and Sander 1981) which has previously been studied in the urban context (Fotheringham, Batty, and Longley 1989; Batty, Longley, and Fotheringham 1989)[1]. The new model, which we call Diffusion Limited Gravitation (DLG), generates structures which visually seem less scattered than those from the SGM. Accordingly, we investigate to which extent the largest cluster outgrows the size distribution.
DLA starts with a seed “particle” at the center of the grid. A new particle performs a random walk starting far from the center. The particle stops once it reaches a cell adjacent to an occupied one. Then the procedure is repeated with a new particle.
We propose to combine the SGM with DLA. The SGM takes place on a square grid. As initial condition we use one occupied cell at the center of the system. The modeling is done according to the following iterative steps.
-
Calculate according to Eq. (1) and normalize so that
-
A random walker starts from an arbitrary cell (can be close to the origin; it can cross urban cells).
-
The random walker stops with probability from Eq. (1). I.e. it stops at site if a random number is smaller than The cell is converted to urban,
-
Repeat from step 1.
Analogous to the original SGM, also DLG involves the parameter which determines how strongly the probability of urbanization drops with the distance. Accordingly, we run the models with different parameter values, i.e. 10 realizations for each. For DLG we use 13 -values within As in each iteration one pixel is added, the number of pixels corresponds to the number of iterations. For SGM the -values are Additionally, for the SGM a normalization factor was used to ensure which implies that the number of pixels approximately increases by 10 during each iteration. We store the model output after every 10th (DLG) or every iteration (SGM). We use a system size of pixels.
-(c)_the_sgm_and_(d)-(f)_dlg_for_different_values.png)
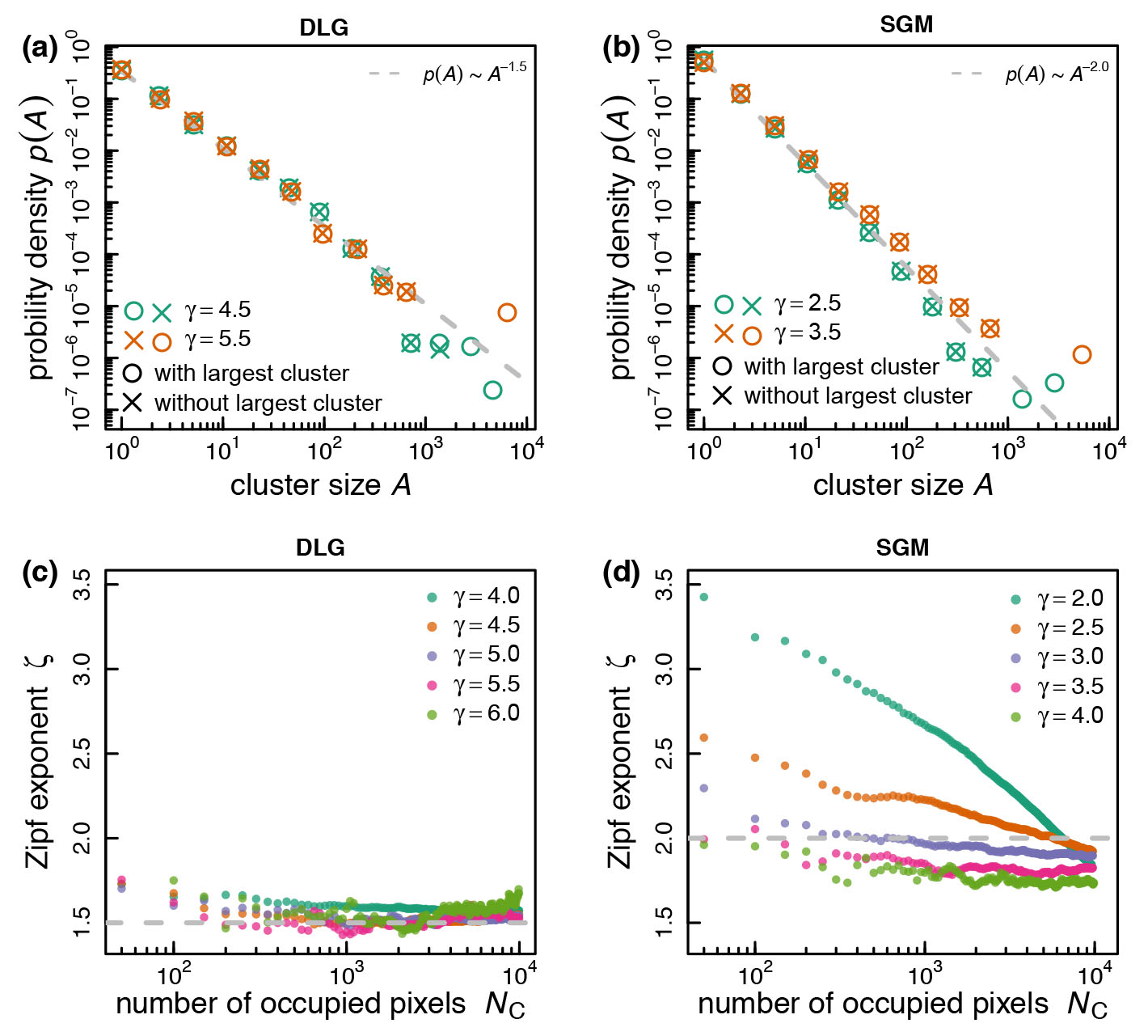
Figure 1 shows illustrative examples of both models. It can be seen that small lead to more scattered and a larger number of small clusters. Vice versa, with increasing the largest cluster becomes dominant. Moreover, for the DLG some of the dendrite structure, similar to the original DLA, can be seen, e.g. Figure 1(e).
As detailed above, previously it was found that the largest cluster outgrows the other ones in various models. Figure 1(d) suggests a more balanced result, i.e. the largest cluster is relatively small compared to abundant smaller clusters. Accordingly, in the following we want to analyze if DLG generates Zipf-distributed clusters and to what extent the largest cluster outgrows.
Zipf’s law for cities (Auerbach 1913; Zipf [1949] 2012; Berry and Okulicz-Kozaryn 2012; Rybski 2013; Nitsch 2005; Soo 2005; Cottineau 2017; Rozenfeld et al. 2011; Ribeiro et al. 2021) can be written as
\[p(A)\sim A^{-\zeta}\textrm{,}\tag{2}\]
where is the probability density function (pdf) and represents the cluster areas (given by their number of urban cells). We use the method proposed by Clauset et al. (2009) to estimate the Zipf exponent (R package “poweRlaw” [Gillespie 2015]). Moreover, we fix the lower bound for the estimation of the exponent to 1. In order to have better statistics we combine the output of 10 realizations with the same or similar number of urban pixels. Please note that differs by 1 from the Zipf exponent when it is obtained from a rank-size plot
For comparison, we also analyze the distribution of a set where the largest cluster of each realization has been removed. We reason that if the estimated Zipf exponents for the sets with and without largest cluster are similar, then the largest cluster is consistent with being drawn from the same distribution. If the exponents differ, then it is not consistent.

Examples of empirically estimated pdfs are shown in Figure 2 (a) and (b). Each panel displays the estimated pdfs for 2 -values and with/without largest clusters. Two observations can be made. First, in both cases the largest cluster seems to be dominant for larger Second, DLG leads to a rather small and for the SGM the exponent seems to depend on
In Figure 2 (c) and (d) the resulting -exponents are plotted as a function of the number of urban cells for DLG and the SGM, respectively. We can see that in case of the SGM there can be a strong dependence (as previously reported [Rybski, García Cantú Ros, and Kropp 2013]), which in case of DLG is much less pronounced. Moreover, for the SGM is found around 2 which is consistent with real-world data but for DLG, is close to 1.5 – a more balanced distribution which is rarely found for real cities.

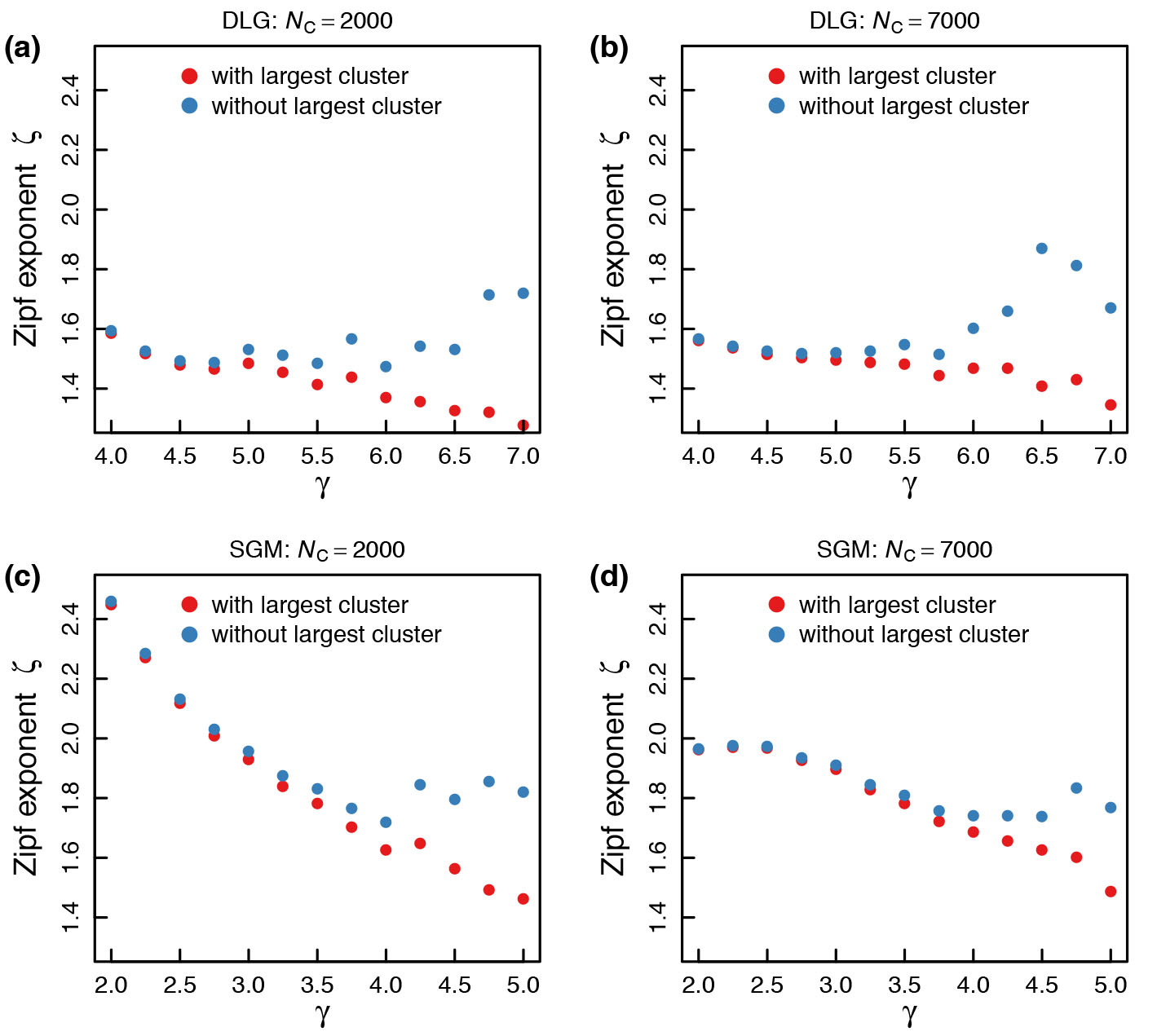
Finally, we study the resulting distributions with and without largest cluster as a function of the model parameter Figure 3 shows the results for 5 % and 17.5 % urban cells. We find that the estimated exponents – in- or excluding the largest cluster – are similar for small but diverge for large In all cases, for small the largest cluster is consistent with Eq. (2) but for larger it generally outgrows. It is important to note that the estimates for very large are less reliable because they are based on critically small sample sizes.
In summary: (i) We propose a new model (DLG) that represents a combination of the well-known DLA with the more recent SGM. DLG is only one possibility and there are other ways of combining DLA and the SGM that can be investigated in future research. Perspectively, SGM could represent a new approach to spatial modeling of human settlements (Strano et al. 2020). (ii) We propose an approach to assess to what extent the largest cluster is consistent with being drawn from the same distribution. From a methodological point of view, more rigorous statistical testing will be necessary, when e.g. the existence of primate cities in real-world data is to be assessed (Linsky 1965). (iii) We find that for both models the largest cluster is compatible with the rest of the distribution if is small. For large values it outgrows.
Funding
D. Rybski thanks the Alexander von Humboldt Foundation for financial support under the Feodor Lynen Fellowship. This work was supported by the German Federal Ministry of Education and Research through the Program “International Future Labs for Artificial Intelligence” (Grant number 01DD20002A).
For completness, we would like to mention the Dielectric Breakdown Model (Niemeyer, Pietronero, and Wiesmann 1984) that was also used for generating urban forms (Batty and Longley 1988; Batty 1991).