
Research Question and Hypothesis
Strava Metro data are being used in bicycling research but are critiqued for bias—both in demographic and trip type—related to who and how the app is used. How well Strava ridership reflects overall bicycle ridership depends on locational factors, for example, how busy a street is, if bicycling infrastructure exists, and safety (Livingston et al. 2020; Nelson et al. 2020). Bias can be addressed by using models that link Strava ridership to counts of all bicyclists, and adjusting for geographic covariates (Jestico, Nelson, and Winters 2016; Roy et al. 2019). Strava data also include a commute label, which may better align with overall ridership. However, there is limited understanding of how Strava trips labelled as commute versus recreation differ in terms of representativeness. Our goal is to understand how the commute label impacts data representativeness by comparing geographic covariates associated with Strava commute and recreational ridership. We hypothesize that commute and recreational ridership samples will be associated with different areas of a city and anticipate that, compared to recreational ridership, Strava data labelled as commute trips better represent overall ridership.
Methods and Data
Study area
The study area is the census metropolitan area (CMA) of Victoria, British Columbia, Canada, with a population of ~367,770 (Statistics Canada 2016) and a bicycle mode share of 6.6%, the highest among Canada’s CMAs (Statistics Canada 2017). Victoria has over 200 km of bicycling infrastructure including ~100 km of regional trails. These paths are the backbone of the bicycling network and are heavily used for both commuting and recreation.
Data and Analysis
We used spatial regression to identify associations between sociodemographic, network, and built and natural environment characteristics for each trip type, and for the pooled sample. The Strava Metro data are from January 1, 2016 - September 30, 2017, and include a spatial file representing the street network and tabular data with aggregate activity counts for each segment. An attribute provided by Strava Metro identifies the count of activities on each segment that were commute trips. We also had area-level summary statistics on the number of unique app users, age-gender distribution, and trip characteristics.
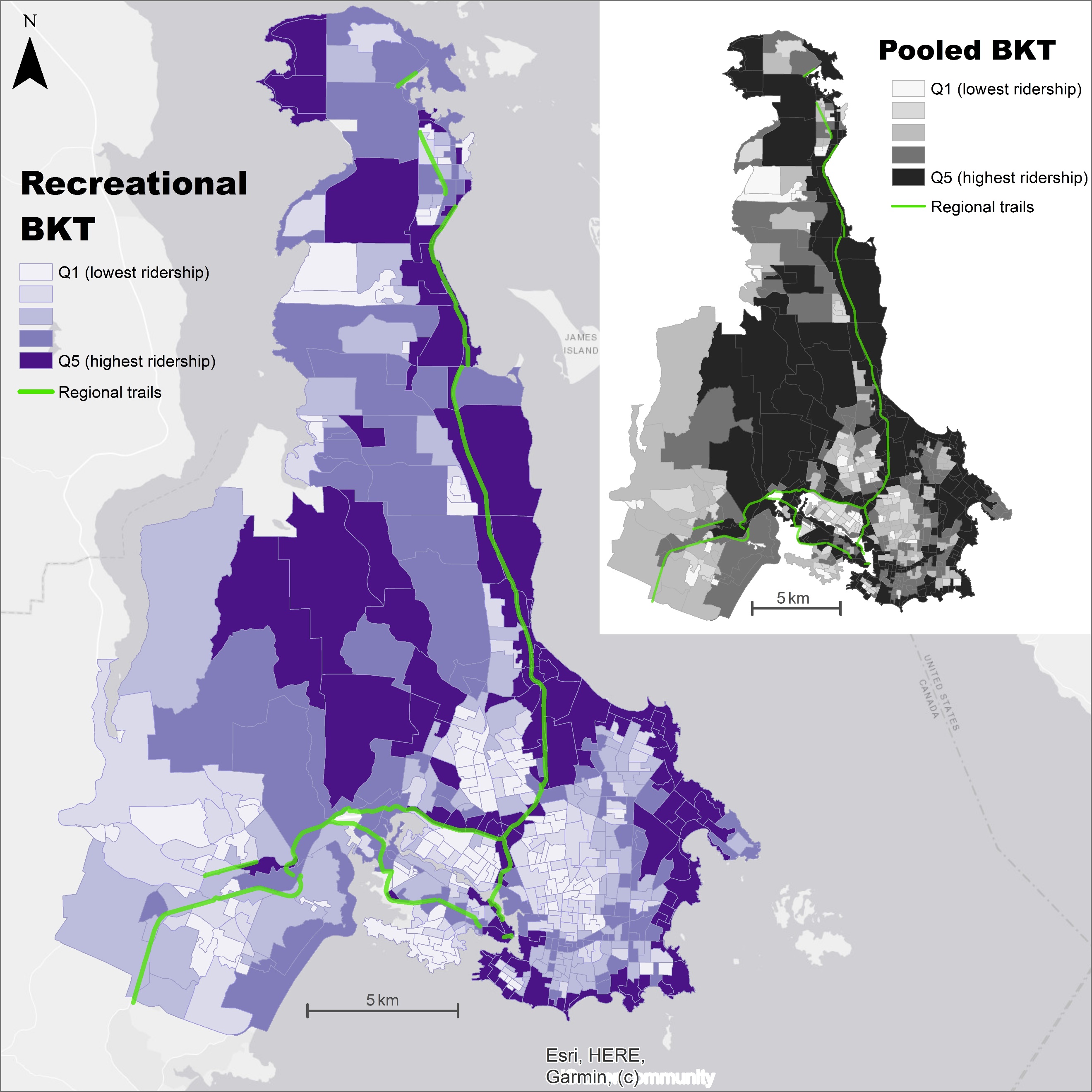
The geographical unit of analysis was the Statistics Canada Dissemination Area (DA; 400-700 people; n = 534). We operationalized Strava ridership as bicycle kilometers traveled (BKT), calculated by multiplying the activity count on each road segment by the segment length and summing the products for each DA (Hochmair, Bardin, and Ahmouda 2019). We standardized BKT by DA total road length and mapped results for each trip type compared to the pooled sample (Figures 1 and 2). Geographic covariates were identified based on previous studies using Strava data, relevance in bicycling studies using conventional data, or local importance to bicycling (Table 1).
We constructed three spatial error models using GeoDa 1.14 (Anselin 2019) and defined spatial neighbors using queen contiguity. The spatial error models use a Maximum Likelihood approach and treat spatially correlated residuals as a nuisance variable (Anselin 2009). The first and second models predicted DA commute and recreational BKT and the third predicted BKT for the pooled Strava sample.
Spatial analyses of areal data are often influenced by spatial autocorrelation (SAC)—the tendency for neighboring areas to have similar values. In ordinary least squares regression, spatial effects can lead to unreliable results as standard assumptions are violated (Anselin 2009). Spatial regression approaches include spatial lag and spatial error models, and model diagnostics indicate which is appropriate (Anselin 2009). We quantified SAC using Moran’s Ii, and used the Robust Lagrange Multiplier (LM) statistic to select the appropriate spatial regression model; the rule of thumb is to choose the model (lag or error) with the most significant LM test statistic (Anselin 2009). We also considered model fit (R2 and AIC).
Findings
In Victoria, there were 12,971 unique Strava app users and 315,200 activities; 49% (n = 155,252) of activities were identified as commutes. Men accounted for 74.9% (n = 9226) of app users, and 64% of users (n = 7,958) were under age 55. Table 2 shows BKT descriptive statistics. Notably, BKT for recreational trips comprised nearly two-thirds of the total BKT (63.5%); so, while there were approximately equal numbers of commute and recreational activities, the recreational trips tended to be longer in distance.
_in_das_(n___534).jpeg)
_in_das_(n___534).jpeg)
Strava activities labelled as commutes showed higher ridership levels in DAs that were closer to universities, had more on-street infrastructure, and higher bicycle crash densities. Recreational activities showed higher ridership in DAs with older populations, more hills and major roads (arterial and collector), and lower intersection density. Strava activities for commute or recreation showed similar levels of ridership in DAs with regional trails, more off-street infrastructure, higher bicycle mode share, bridges, and closer proximity to the ocean.
Using Strava data labelled as commute activities, instead of a pooled sample, may mitigate bias in Strava data and better represent ridership patterns of people of all ages and abilities. When using only the commute activities, we saw different spatial patterning in ridership and found that activities tended to be in areas with bicycle infrastructure, lower levels of safety, and around universities. Recreation activities were more common in areas with major roads, steep slopes, and lower intersection density—factors that are typically less preferred and less safe for bicycling (Teschke et al. 2012; Winters et al. 2010). Other important covariates were common across commute and recreational trips (regional trails, off-street infrastructure, bicycle mode share, bridges, and proximity to the ocean) and would be selected from either the commute or pooled sample. This suggests that if a planning exercise aimed to model overall ridership using Strava data and geographic covariates, a distinct set of covariates would be selected if only the commute data were used. In Victoria, commuting accounted for 49% of all Strava activities and 36.5% of the total distance (e.g., BKT). From other Strava analyses we learn the proportion of commute trips varies across cities (e.g., 21% in El Paso, Texas (Lee and Sener 2019), 85% in Milan, Italy (Sunde 2019). If interested in modeling all ages and abilities ridership, researchers and practitioners should consider using only commute data, at least in cities where the sample is sufficiently large.
Acknowledgements
The authors would like to acknowledge Strava for providing the data.