Research Question and Hypothesis
Understanding travel patterns is critical for transportation planning and monitoring impact of policy and infrastructure. Traditional travel data collection techniques, like GPS-based travel surveys (Stopher, FitzGerald, and Zhang 2008), are prone to underreporting of trip activity by participants (Bricka and Bhat 2006). As a result, sensor data collected by health apps on smartphones or wearable devices have emerged as a method for collecting data on transportation mode choices and travel patterns.
Researchers (Zhou and Hu 2008; Ellis et al. 2014) typically use GPS and accelerometry data from wearable health monitoring devices with accelerometer and GPS sensors built within the same device. Integrating these datasets from different platforms is challenging because of the varying space-time resolutions each device has. Some studies (Stenneth et al. 2011; Hemminki, Nurmi, and Tarkoma 2013) demonstrated how tree-based machine learning algorithms could be applied to GPS data collected at a frequency of 15 seconds for GPS data from mobile phones to 1.2 s from accelerometers for mode detection. However, there is a major gap in determining an optimal time window generalizable across multiple data platforms for achieving the highest level of prediction accuracy when it comes to classifying transportation modes.
The goal of our study is to demonstrate how classification of GPS and accelerometer collected from two different platforms into transportation modes - active (bike/walk), private (car) and public (trams/railways/subway), is more accurate when features from both sources are combined. We hypothesize that classification accuracy improves when data are combined using varying window sizes to tackle noise filtering from the fused data. To this end we use a supervised classification algorithm Support Vector Machine (SVM) with a radial basis function.
Methods and Data
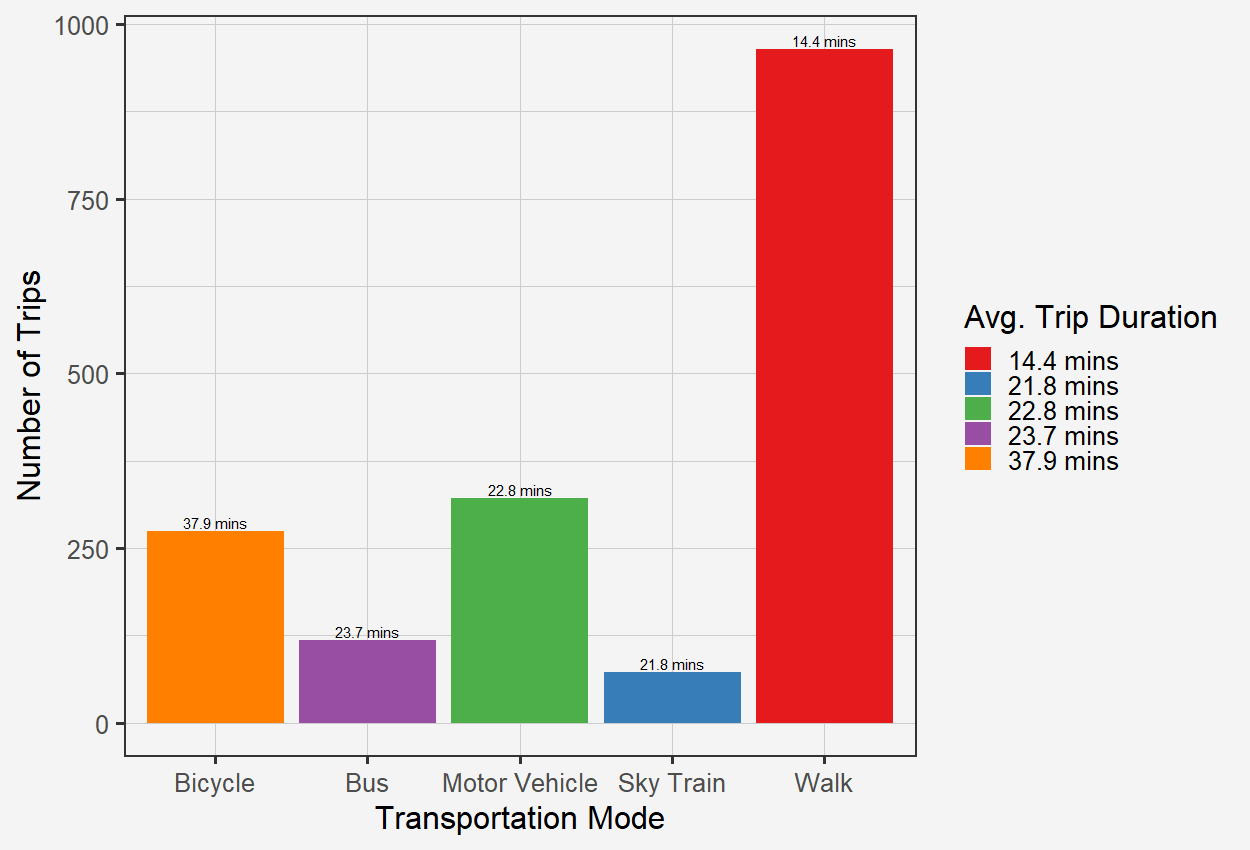
We recorded 4071 user-defined trips after removing stops and congestions from 12 users for a period of 6 months from a smartphone application Itinerum (Patterson et al. 2019) which collected GPS data and wrist-worn accelerometer (GENEActiv 2020). The data were analyzed at 1-minute temporal resolution and included 93,772 data points. Participants were from the cities of Vancouver and St. John’s, Canada. All trips were pre-labelled by participants and categorized into 5 different travel modes with varying trip durations (Figure 1), with an average trip duration of 24.5 minutes for all trips (min = 2 mins, max = 62 mins, bicycle= 37.9 mins, bus = 21.8 mins, motor vehicle = 22.8 mins, sky train = 23.7 mins, walk = 37.9 mins). Walking (n=964) followed by motor vehicles (n=321) were the most common modes in the dataset.

We computed summary statistics of speed and vector magnitude of acceleration –from raw GPS and accelerometer data (Table 1) and used signal processing functions (Table 1) to extract a total of 37 features which were used as input to the SVM algorithm. We also examined different window sizes of 3, 5, 7, and 10 seconds by summarizing the mean of the raw features in each time period in order to remove noise from the raw data. All analysis were performed using R 3.6.1 and ArcGIS© 10.7.1.
We applied a supervised classification algorithm - Support vector machines (SVMs) to our input feature set in order to classify travel modes. SVMs, first introduced by Cortes and Vapnik (1995) have been heavily used in data mining for different purposes (Hamel 2011; Li et al. 2011; Anguita et al. 2012) and are a non-probabilistic binary classifier that separates two classes by determining an optimal separation hyperplane. We used a multiclass separation using a radial basis function to classify all five travel modes by coupling binary classifier probabilities (Wu, Lin, and Weng 2004). 70% data were used for training the SVM model and the remaining 30% for testing with a 10-fold repeated cross-validation with 3 repeats across 3 feature set combinations (only GPS, only accelerometer, both GPS and accelerometer). Using a Synthetic Minority Sampling Technique (SMOTE) a resampling technique (Chawla et al. 2002) we accounted for the imbalance in trips among the five modes and calculated the area under the curve (AUC) (Hand and Till 2001) from resampled data to test the average accuracy of our model we use Equation 1. AUC score measures the separability between the estimated probability distributions that a randomly chosen member of one class belongs to that particular class compared to other classes.
AverageAccuracy=∑ki=1tpi+tnitpi+tni+fpi+fnik; where, k = no.(1)of classes, tp = true positive, tn = true negative,fp = false positive, and fn = false negative
We also report the F1-score, precision and recall based on sensitivity and specificity (Altman and Bland 1994) of each mode along with the balanced accuracy (Velez et al. 2008). Finally we visualize the classification accuracy using a confusion matrix for the best feature combination. Our study is a proof of concept for sensor fusion and window size, so we do not compare different machine learning methods.
Findings
We found the model accuracy varied with the type of data sources and window sizes used. The overall accuracy of the fitted model improved with increasing window size with the highest mean accuracy (91.1%) achieved by combining both GPS and accelerometer features (Table 2). Among all scenarios, the window size of 7s had the lowest variance in accuracy (Table 2) using SMOTE to account for imbalanced classes. The accelerometer features had the lowest mean accuracy of 55.5%.
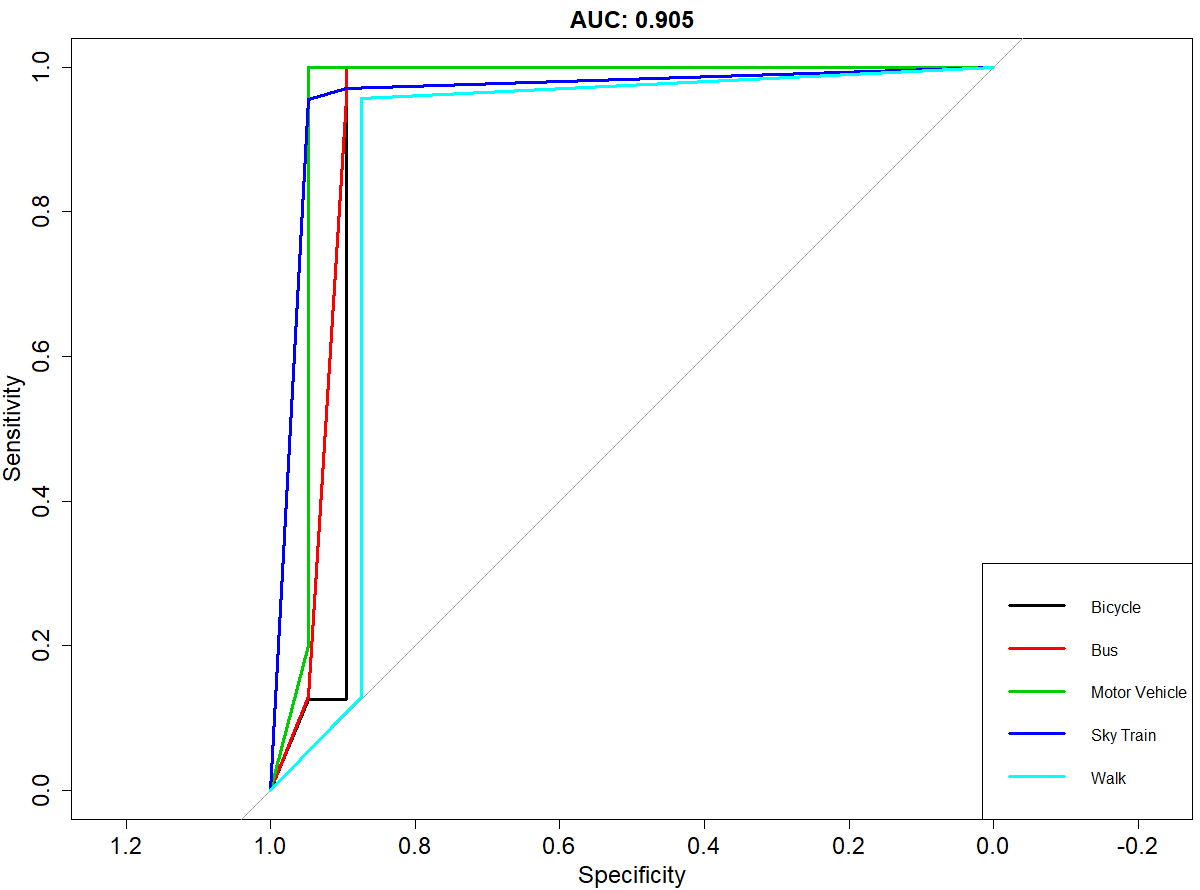
The best model fit with 90.9% accuracy was obtained by combining both GPS and accelerometer data with a 7s window. The overall AUC score was 0.905 (Figure 2) for all 5 classes combined. The maximum accuracy (95% CI) of the SVM classifier in the 7s window when we fit combined features showed an improvement by nearly 9.5% from only GPS and 30.1% from only accelerometer features respectively.

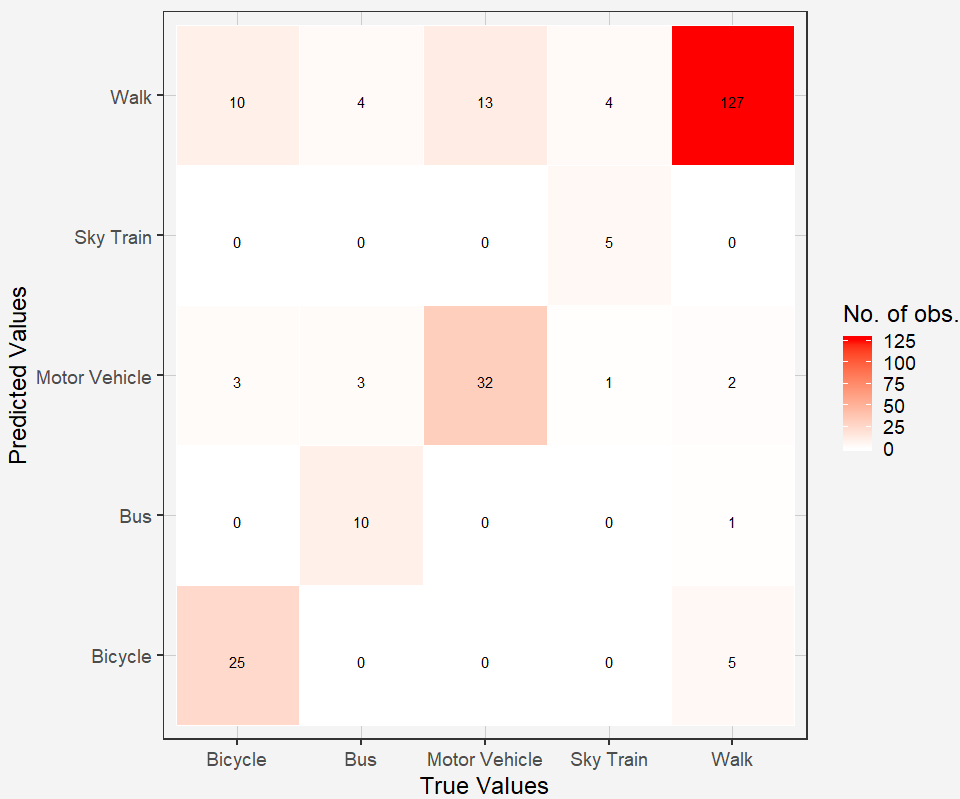
The confusion matrix in Figure 3 shows the classification accuracy of each mode on the 30% testing data. Overall, public transportation modes were most accurately classified (Table 3) followed by bicycling – after accounting for imbalanced data.

Our model is a good approximation of human mobility as per previous studies (Hemminki, Nurmi, and Tarkoma 2013; Widhalm, Nitsche, and Brändie 2012) and would work well with similar populations. Our methods can be used to inform planners about the most preferred travel modes in a city and to understand how modes change with interventions using open reproducible methods for decision making purposes.
Acknowledgments
The authors would like to thank INTERACT team for providing valuable feedback and supporting the work. The study is supported by a grant #IP2-1507071C from the Canadian Institutes of Health Research. This study was approved by the Memorial University Interdisciplinary Committee on Ethics in Human Research (20180188-EX).