1. Questions
Machine learning algorithms have emerged as integral tools in transport research, particularly in the field of crash severity prediction (Malik et al. 2021; Yan and Shen 2022; Yang, Zhang, and Feng 2022), contributing to the reduction of car crash accidents with the design of safety campaigns, improved traffic laws, advancements in vehicle safety and traffic management systems (Fisa et al. 2022). In addition, crash severity prediction, utilizing machine learning models, can be used to optimize emergency medical services allocation by identifying injury severity. Determining the most effective models for injury severity prediction is crucial for resource allocation. Moreover, understanding critical factors in crash severity prediction can contribute to reducing accident occurrences, enhancing overall road safety strategies.
2. Methods
The data for this study covering the time period of 2018-2022 was obtained from the portal of the NSW Department of Transport (https://opendata.transport.nsw.gov.au/dataset/nsw-crash-data), with 20 variables and 57,240 observations selected. Variables associated with specific locations, IDs, or a high percentage of missing data were excluded to prevent potential overfitting. Additionally, variables irrelevant to this research, such as school zones, or those containing post-crash information like the number of injuries or fatalities, which could bias severity predictions, were omitted. Descriptions for each value utilized in the study were sourced from the portal’s manual and are provided in Table 1 below.
For our dependent variable (‘Degree of crash - detailed’), the classes are separated into ‘Fatal’ with 1,423 observations (2.5%), ‘Minor/Other injury’ with 7,582 observations (13.3%), ‘Moderate injury’ with 20,349 observations (35.6%), ‘Serious injury’ with 18,115 observations (31.6%) and ‘Non-casualty (towaway)’ with 9,771 observations (17%). This distribution suggests that our data is imbalanced, potentially leading to biased predictions that neglect minority classes. To address this, we are using SMOTE (Synthetic Minority Over-sampling Technique), which generates synthetic instances of underrepresented classes by interpolating existing ones. This approach aims to balance the dataset, enhancing the robustness and accuracy of our model in handling diverse crash severity cases while minimizing bias towards the majority class. (Chawla et al. 2002).
Utilizing a 70% train, 30% test data split, we apply an ensemble model of: Random Forest, XGBoost, AdaBoost, LightGBM and CatBoost. These models were chosen due to their robust generalizability and reduced overfitting abilities (Hastie, Tibshirani, and Friedman 2009). These models will employ a soft voting mechanism, where the final prediction is based on the weighted average of probability estimates from each model, enhancing overall prediction reliability. Hyperparameter tuning will further refine these models, and optimize their performance. Table 2 below provides an overview of each model used in the analysis, and a list of the optimal hyperparameters identified through the grid search process.
Since the dataset was balanced using SMOTE, traditional measures like accuracy will not be incorporated due to its limitations in reflecting the true predictive power of the model, especially in scenarios where class distribution has been artificially altered. Instead, we will evaluate model performance using precision, recall, F1 score, and AUC-ROC score. The AUC-ROC (Area under the Receiver Operating Characteristic curve), assesses the model’s discriminative power to differentiate between classes at various thresholds, providing an extensive evaluation of its effectiveness in classifying balanced data. (Bradley 1997).
In addition, feature importance will be computed by weighting the importance scores from each model proportional to their AUC-ROC scores (Wang and Tang 2009), followed by averaging and normalization of these values. This method ensures that the contribution of each feature is weighted according to the model’s performance. Furthermore, we will identify the most common variables among the top three features, as well as additional selected features, in instances of fatal crashes. This approach aims to isolate the key factors that significantly elevate crash severity, guiding preventive measures more effectively.
3. Findings
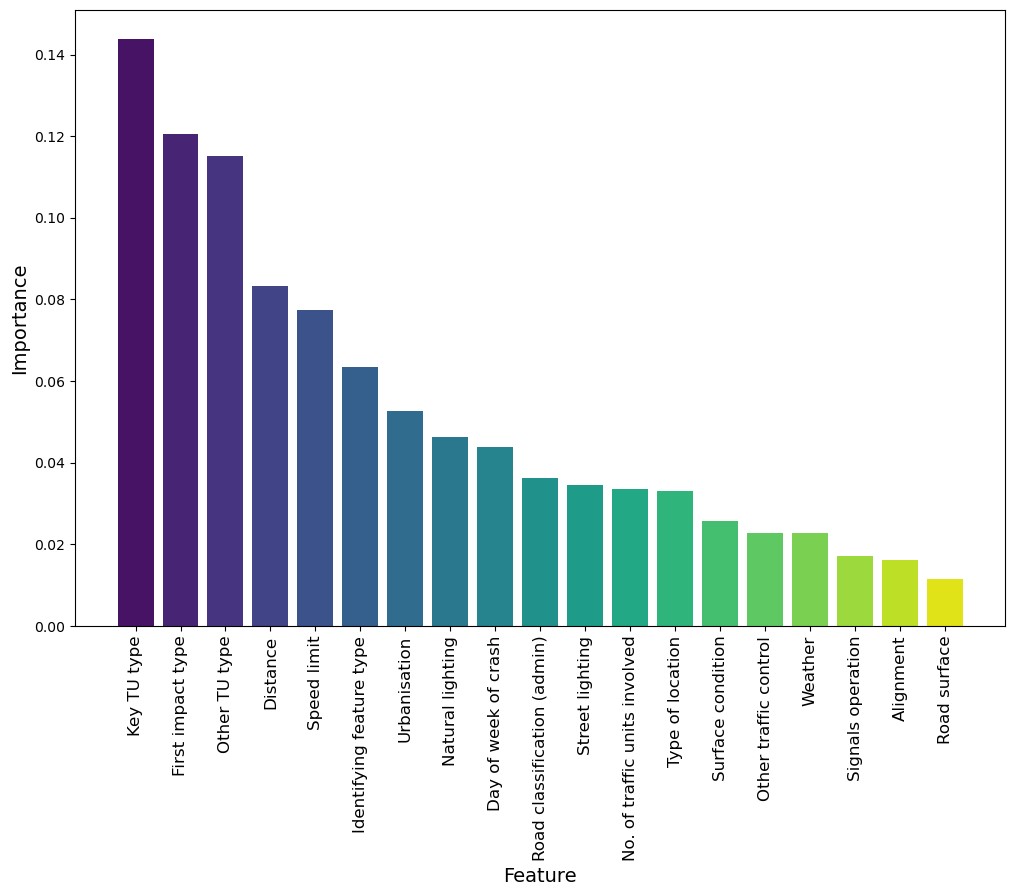
We begin our findings with feature importance, revealing ‘Key Traffic Unit Type’ as the leading indicator, reflecting the substantial role of the primary vehicle involved in the crash. Subsequently, ‘First Impact Type’ is identified as the second most critical feature, indicating the initial collision’s manner is also a major factor in the severity of the crash. As would be expected based on the previous two features, ‘Other Traffic Unit Type’ ranks third, acknowledging the influence of additional parties involved in the incident.

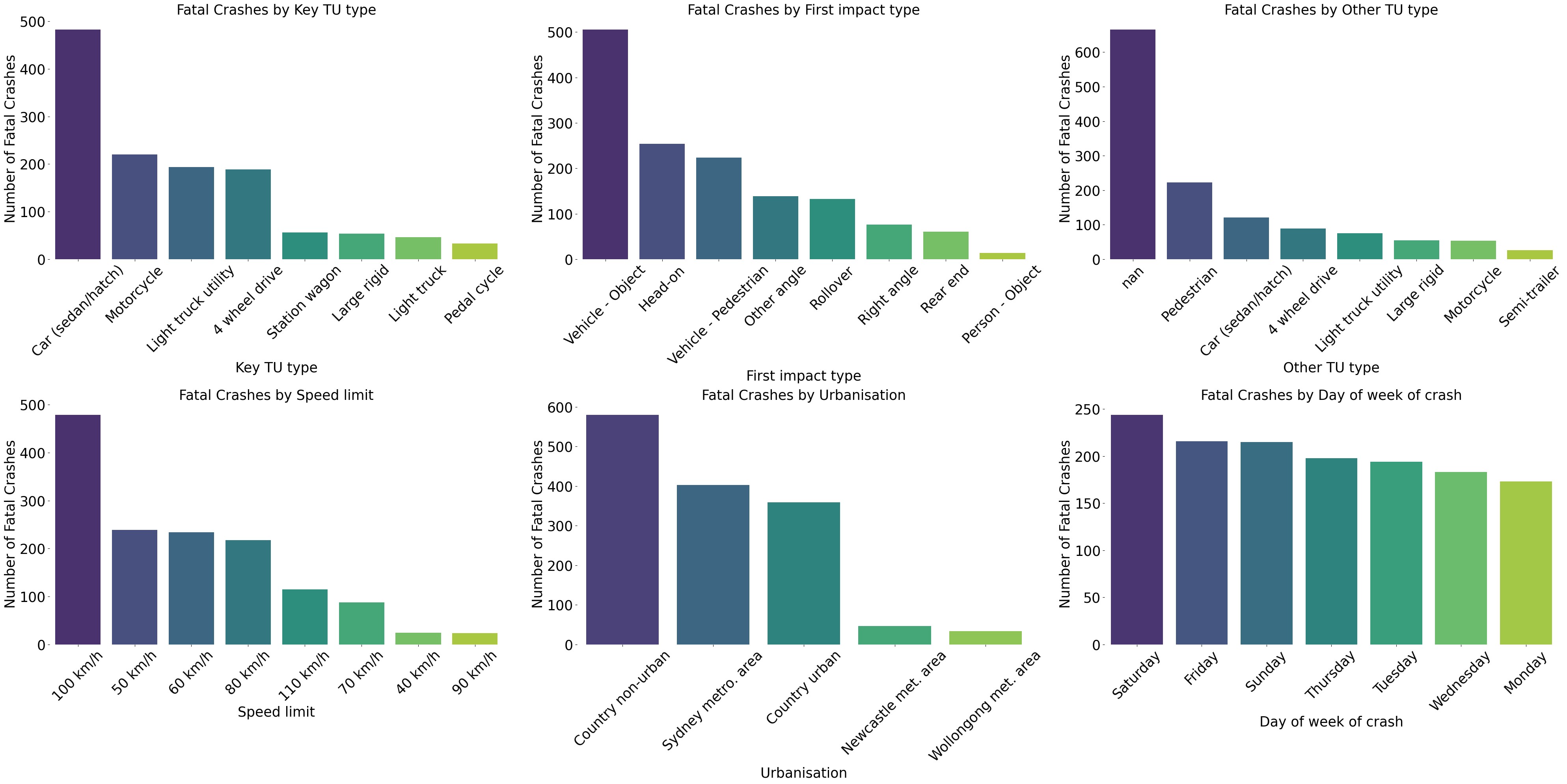
The analysis of common variables in fatal crash instances (Figure 2) shows that sedans/hatchbacks, motorcycles, and light trucks are most frequently involved. The primary impact types are vehicle-to-object and head-on collisions, with pedestrians often appearing as a prominent secondary factor (since vehicle-to-object collisions are the most frequent, the expectation of no secondary traffic unit involvement as the top choice is reasonable). The day of the week, speed limit, and urbanization were selected as additional features due to their relevance in shaping policies aimed at enhancing road safety and emergency response accessibility. The findings suggest that, fatal crashes occur more on weekends specifically on Saturdays, particularly in country non-urban Local Government Areas (LGAs) and Sydney metropolitan area, with speed limits of 100 km/h and 50 km/h being the most usual settings for such accidents.

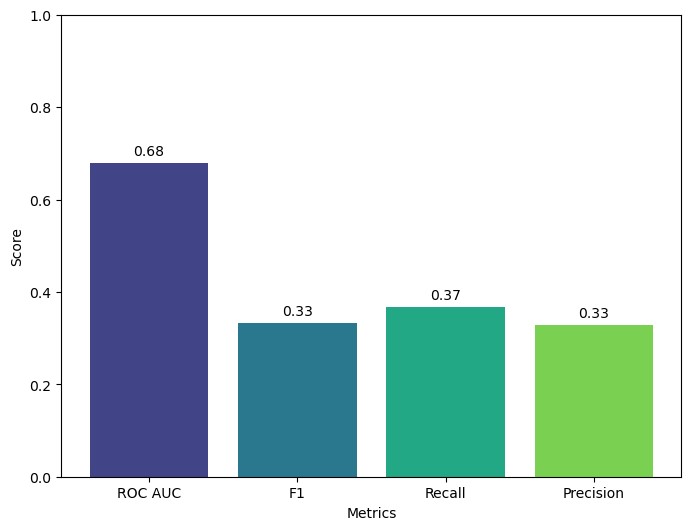
Based on a model evaluation across four metrics depicted in Figure 3 below, the ROC-AUC score reached 0.68, indicating a moderate capability of the model to distinguish between classes. Additionally, the F1 score, Recall, and Precision remained consistent, with respective scores of 0.33, 0.37, and 0.33, reflecting a moderate-to-low performance in identifying true positives and true negatives. These findings highlight the model’s reasonable discriminative ability while also suggesting opportunities for improvement in its predictive balance.

In conclusion, our analysis presents the predictive accuracy of an ensemble of selected machine learning models and key variables influencing crash severity, offering valuable insights for traffic safety enhancement. While factors like ‘Key TU type’ and ‘First impact type’ significantly impact crash outcomes, further research should explore the less influential variables such as ‘Surface condition’ and ‘Signals operation’. Future work could integrate more granular data, such as driver behavior or vehicle condition, and employ advance machine learning methods such as SVM and data balancing techniques such as ADASYN or SMOTE-Tomek to refine predictive accuracy. This ongoing research can be significant in developing targeted strategies to reduce road accidents and enhance public safety.